Our Blueprint for a Digital Highway for Continous Software Delivery

Establishing Continuous Software Delivery does not have to be difficult! Learn how to leverage our “Blueprint for a Digital Highway” as market best-practice vision for software development and operations. Understand which key capabilities are critical to succeed in achieving delivery speed and balancing quality at the same time. See how ML-driven and Cloud-driven practices support the adoption of next generation technology, a SRE-driven, digital operating model, and a culture for reliability engineering.
Introduction
In previous blog posts, we have introduced some of the key capabilities to establish the Digital Highway for Continuous Software Delivery:
- Effective Site Reliability Engineering as methodology and operating model
- SLO Engineering, Service Level Objectives and Error Budgeting as capabilities to manage and operate services according to expectations
- Observability, Monitoring and AIOps as architectural capability
- Observability and OpenTelemetry as Service Level Indicator sources
To recap, the goal of the Digital Highway is to:
“Ensure Service Level Objectives (SLOs) in the age of digital transformation, cloud & DevOps while keeping budget under control and leveraging value-add cloud-native, Machine Learning and AI-driven technologies & best practices”
With this post, we want to show how we at Digital Architects Zurich combine above key capabilities, additional building blocks and prerequisites into a blueprint for the Digital Highway. Further, we will illustrate where potential challenges are and what solution patterns can be leveraged to overcome these.
Prerequisites to build the Digital Highway
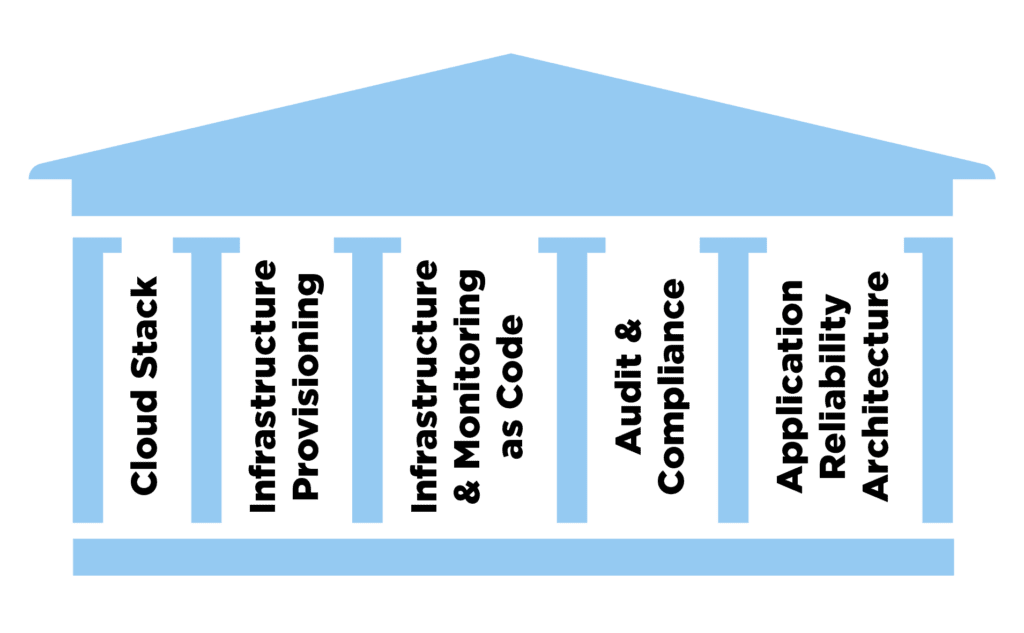
The foundation of the Digital Highway consists of five key pillars that are themselves built on what we typically call the “Framework & Guidelines for the Cloud”. This framework is a key strategic item to focus activities when developing and deploying applications for the cloud. It consists of architectural patterns on how to create cloud-able applications, instructions for developers how to code these and guidelines how to deploy and operate in a cloud-native (or hybrid) environment. The framework further allows to identify shortcomings of legacy environments early and thus makes a cloud transformation journey more efficient.
The five key pillars on top of the Framework & Guidelines that we define as key prerequisites are the following:
- Cloud Stack – leveraging “as a service” capabilities for service/application, platform, and infrastructure. Priority of SaaS over PaaS over IaaS is determined by the framework and adopted to customer needs
- Automated Infrastructure Provisioning – done in an automated way and “as Code” to allow packaging of deployment information alongside the application code
- Monitoring as Code – to give developers an efficient mean to interact with observability and monitoring configuration (also see building block 2 and our Webinar Observability as Code)
- Audit & Compliance – built in checks for compliance to ensure any audit requirements, as well automated as far as possible to achieve velocity
- Application Reliability Architecture – leveraging best-practice coding and architectural patterns to build resiliency and reliability into applications
Building block 1: Continuous Delivery pipeline to transport artefacts
The goal of software delivery is to turn code into applications and deliver them safely to business and users, fulfilling their expectations and requirements. The need for more frequent releases and faster delivery speed required IT teams and organisations to reconsider their application development and release strategies over the past few years. Increasing velocity (see Agile Velocity) and maintaining quality at the same time required changes in operating and collaboration models and more technological changes by adapting code control, code maintenance and quality assurance. The introduction of Agile, DevOps and Site Reliability Engineering allowed to ensure smooth collaboration between the responsible teams for delivery and operations. Likewise on the technical side, the introduction of code pipelines and automation in testing/release were introduced to ensure quality and velocity of software delivery.
Let us walk through below visualisation of the Continuous Delivery pipeline and look at key capabilities from left to right:
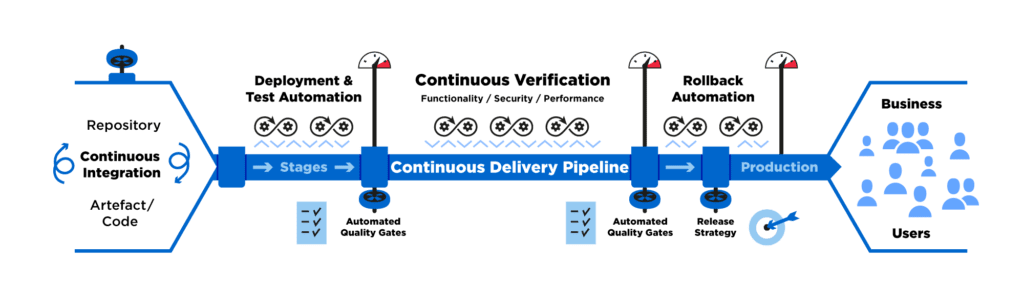
- Developers create code and commit frequently – good practice in any modern software delivery organisation
- Continuous Integration takes and builds the committed code upon check-in and validates it: compilation, unit testing and static code analysis. Upon success, it merges to trunk and prepares a deployable artefact in a repository
- Continuous Delivery pipeline gathers the artefact from the repository and pushes it through testing and validation, in sequential stages / environments. To do this with as little (slow) manual intervention as possible, it is key to have automation in place
- Deployment Automation including automated test environment provisioning (see the fundamental pre-requisite in the previous chapter)
- Test Automation for functional, performance and security, we call this Continuous Verification, also see the second building block of AIOps for analytics of monitoring data.
- Quality gates are used to document quality checks and progress between stages, either in an automated fashion (i.e., upon completion of all mandatory checks and tests) or with manual approvals where still required.
- Rollback Automation and Continuous Verification are key if you near the goal of Continuous Deployment where committed code automatically gets pushed to production without manual intervention. In case of failures or observed degradation in production, automatic rollback is triggered to a previous artefact.
- To minimise risk of user impact in Continuous Deployment scenarios, it is recommended to implement incremental Release Strategies, e.g., canary deployments.
Based on our experience and because of the vast breadth of required capabilities, there is not “one technology” that can serve as “the” Continuous Delivery pipeline. Instead, we leverage intelligent orchestrator technology at the core that can steer the many other building blocks required for automation, quality assurance and releasing.
Building block 2: AIOps to analyse Observability data and other metrics
In a previous blog post, we established the Open Observability-based Instrumentation & AI-able Streaming Architecture (see OOBASA, Digital Architects Zurich). Some key aspects of this architecture blueprint are:
- Big Data capability to integrate and prepare the observability data collected from several data sources (Open Telemetry, Cloud APIs, Legacy Built-in Monitoring, etc…)
- Open and flexible Machine Learning Engine as domain agnostic solution: including ready-made recipes / algorithms and allowing «customer analytics as a code»
- Automation and alerting engine (ML/AI-driven) to
- Analyse and correlate collected information and automatically identify problems and their root causes
- Inform change management of any automated changes (e.g., remediation)
- Raise correlated alerts in incident management
We have a broad set of data types that we want to process:
- Observability Metrics, focusing on the application (see Observability and MELT, Digital Architects Zurich).
- DORA Metrics (or similar) that focus on the software delivery process’ performance (see DORA Metrics, Google).
- Metrics from legacy monitoring tools or APM tools
As these data types can come from a diverse set of sources and in a large volume, we need an efficient way to process and analyse this large set of data. The type of facility to do this automatically is Artificial Intelligence for IT Operations (see AIOps, Gartner or AIOps, Wikpedia). With AIOps we apply intelligence / machine learning to the data to consolidate, correlate and automate where required.

Building block 3: SRE-enabled operating model to ensure velocity
The last building block is to apply Site Reliability Engineering / Service Reliability Engineering (SRE) as operating model to run applications efficiently and keep the delivery pipeline under control. We have discussed this in a previous blog post.
The main goal of SRE is to balance speed of delivery and quality/stability. With a ML-driven, standardised Continuous Delivery pipeline, with the technical capability of Observability (not only technical, but also changing responsibilities (see Effective SRE: Observability), and the AIOps engine to process this data efficiently and automate intelligently, the SRE team now has the required means to fulfil their role.
Key components for enabling SRE and SRE teams are:
- Visualisation: Dashboard as Code to visualize pipeline and application metrics
- Observability: as source for analytics and visualisation
- AIOps: to intelligently process data and automate incident management
- Incident management: ensure structured, fast response and recovery of services
- Change management: automated or manual, to bring auditable changes to production

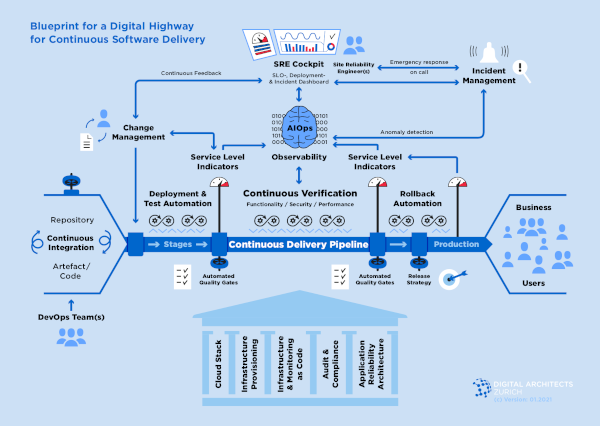
Completing the picture of the Digital Highway
We combine all above building blocks into our “Blueprint for the Digital Highway for Continuous Software Delivery and Software Operations”:
How to Apply to Other Areas: Digital Highway for MLOps
Our partner cell Machine Learning Architects Basel are working with customers based on their “Digital Highway for End-to-End Machine Learning & Effective MLOps.” Head over to their website for more information on how to successfully implement an end-to-end approach for reliable and continuous machine learning delivery and operations.
Get in Touch to Learn More
Please let us know if you have comments or would like to understand how Digital Architects Zurich can help you creating your own Digital Highway. We also provide training and engineering power for your team to effectively set-up all building blocks, from Site Reliability Engineering (SRE), Continuous Delivery pipelines to AI-driven Continuous Verification and ML-driven Observability.
References
- Agile Velocity, Agile Alliance, 2021
- Site Reliability Engineering, Google, 2017
- Webinar: Embedding Security in your Digital Highway for Continuous Software Delivery, Digital Architects Zurich & Snyk.io 2021
- Webinar: Democratising Continuous Software Delivery, Digital Architects Zurich & Harness.io, 2021
- The Digital Highway for End-to-End Machine Learning & Effective MLOps, Machine Learning Architects Basel, 2022
- DORA Metrics, Google, 2020
- AIOps, Wikipedia, 2022
- Definition of AIOps, Gartner, 2022
- Effective Site Reliability Engineering, Digital Architect Zurich, 2020
- Effective SLO Engineering and Error Budget, Digital Architects Zurich, 2020
- Effective SRE Tooling for self-service Monitoring and Analytics, Digital Architects Zurich, 2020
- Effective SRE Key Capabilities: Observability, OpenTelemetry and MELT, Digital Architects Zurich, 2022
- Reliability: the backbone of successful businesses, Digital Architects Zurich, 2021
- Webinar: Observability as Code, Digital Architects Zurich & Splunk, 2021